About Jingwen
Jingwen is a fourth-year PhD student at University College London (UCL) Centre for Doctoral Training (CDT) in Foundational AI, working on semantic SLAM-related research under the supervision of Prof. Lourdes Agapito. Jingwen’s most well-known research work is DSP-SLAM, an object SLAM system that is able to reconstruct fully detailed shapes of objects. He also showed a very impressive real-time 3D reconstruction video demo of hundreds of cars on one sequence of the popular KITTI dataset. The work was presented at the prestigious International Conference on 3D Vision (3DV) in 2021.

Jingwen joined Slamcore as a research scientist intern from July 2022 to June 2023 working under the supervision of Dr. Alexander Vakhitov. During his internship, Jingwen also had the chance to collaborate with other Slamcore researchers including Dr. Juan Tarrrio and Slamcore CTO Dr. Pablo F. Alcantarilla. Jingwen helped to develop a new real-time semantic mapping system for Slamcore that is more efficient and accurate than previous methods. The work has been submitted to IEEE Robotics and Automation Letters (RA-L) for optional presentation at IEEE Intl. Conference on Robotics and Automation (ICRA) 2024. This blog will briefly discuss the new semantic mapping system developed by Jingwen.
SeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation
Starting from the famous SemanticFusion work from McCormac et al., most of the semantic SLAM/mapping algorithms follow a similar two-step paradigm where 1. A 2D network processes individual input RGB-D frames and outputs the semantic labels; and 2. 2D label predictions are lifted to 3D via back-projection and fused with historical predictions via Bayesian Fusion.
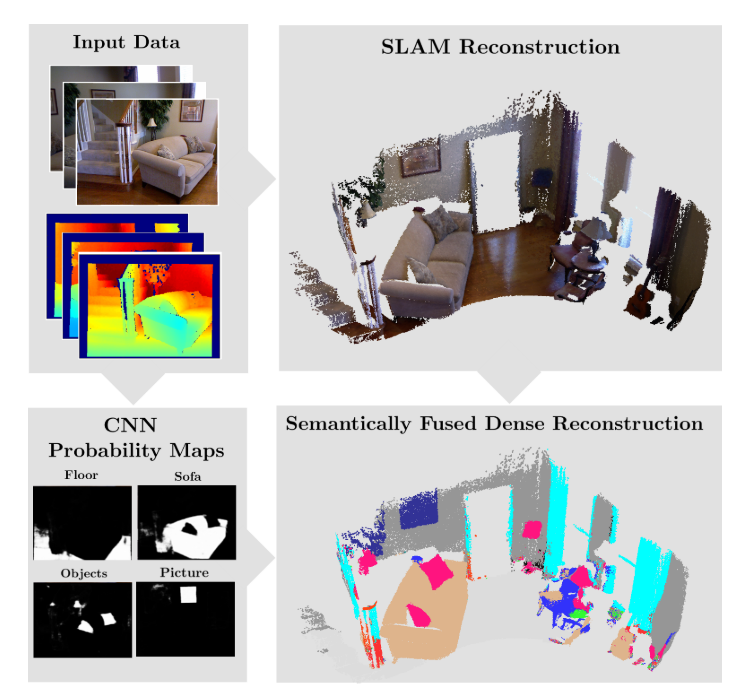
Fig. 1: Traditional two-step semantic mapping pipeline from SemanticFusion.
This pipeline has two issues: First, most of the 2D networks process the input RGB/RGB-D frames separately without encoding any history or local context information. Second, the process of obtaining the predicted semantic labels doesn’t explicitly consider any 3D spatial information, which has been proven very important to achieve SOTA accuracy by 3D network-based methods, such as SparseConvNet, MinkowskiNet, etc.

Fig. 2: Processing each frame individually doesn’t encode any information from previous frames and yields more artifacts (mid-row). Injecting local context information can improve the 2D label prediction.
SeMLaPS addressed the above two issues while still maintaining real-time performance by 1. Proposing a 2D Latent Prior Network (LPN) that leverages differentiable feature rendering to encode cross-frame information to obtain better, more temporal consistent 2D label predictions; and 2. Leveraging a Quasi-Planar Over-Segmentation (QPOS) algorithm to group raw voxels into boundary-preserving segments and applying SegConvNet (3D convolution) at segment-level.

Fig. 3: Online semantic mapping process of SeMLaPS: First, our LPN outputs better 2D semantic labels which are then lifted to 3D and fused over time with Bayesian fusion. Then, QPOS groups the surface voxels into segments and our SegConvNet refines the final segmentation labels by applying convolution at segment-level.
2D Latent Prior Network

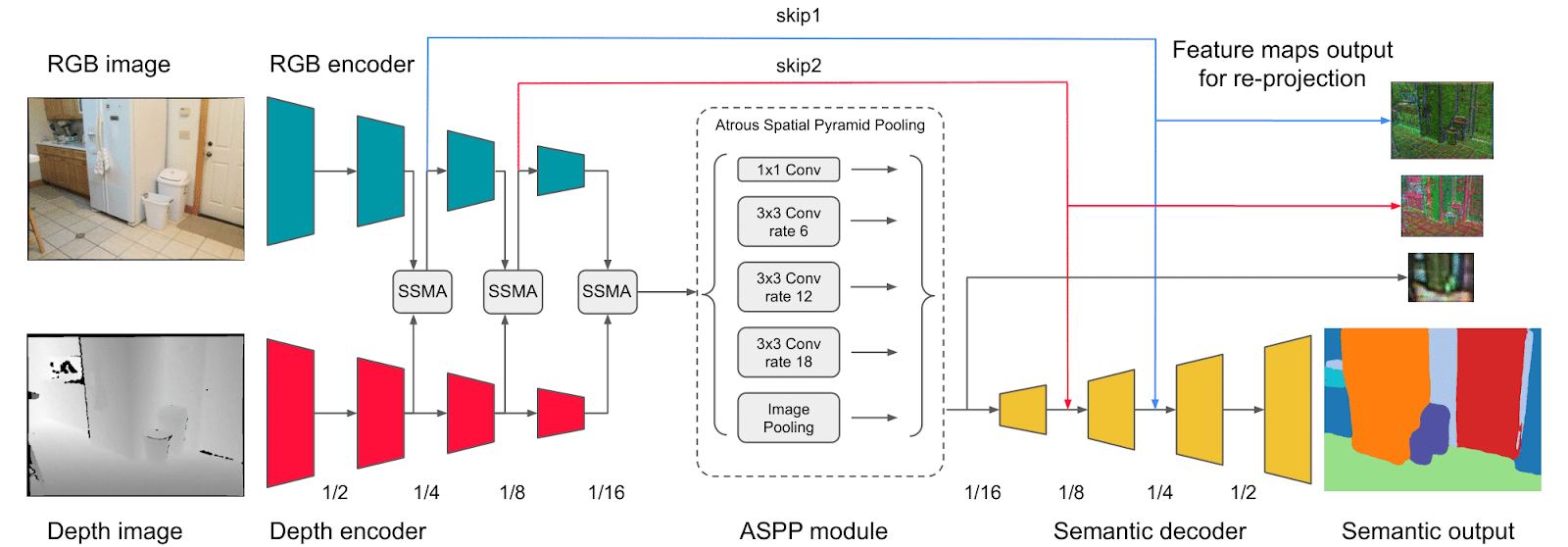
Fig. 4: Our LPN architecture and different modes of injecting prior features at training and inference.
Our LPN outputs better multi-view consistent 2D labels by injecting feature maps of neighboring views into the reference view. The training takes advantage of fully differentiable feature map rendering while during inference LPN can operate with great flexibility from three perspectives:
- It can take an arbitrary number of views as input.
- It can process the frames in a sequential manner without the need to recompute feature maps of previous frames each time.
- While the feature re-projection requires depth input, the feature extractor can rely on both RGB-D or RGB only.
QPOS + 3D SegConvNet
Applying 3D networks directly on raw primitives, i.e. points, voxels is too computationally heavy for real-time application. Therefore, we group the raw primitives (here we use voxels) into segments where each segment contains several hundreds of voxels/points. This design choice allows us to apply 3D convolutions on several thousands of segments instead of several millions of points/voxels. Finally, our SegConvNet applies 3D convolution at segment level and outputs the final refined 3D labels.

Fig. 5: An example of a 3D map based on segments.
Results and Summary
By addressing the two issues with a traditional pipeline, SeMLaPS could significantly improve the semantic mapping accuracy matching the state-of-the-art 3D network-based methods on public benchmarks.

Fig. 6: Qualitative results on ScanNet dataset.
Moreover, cross-sensor generalization is a very important problem in the real deployment of robotic perception systems: for example, how well a model trained on depth obtained from Kinect sensors, such as ScanNet dataset, could perform on sequences captured with Intel RealSense sensors? Experiments show how SeMLaPS could achieve much better cross-sensor generalization than 3D network-based methods.

Fig. 7: Qualitative results on self-captured sequences with RealSense d455. SeMLaPS achieves much better cross-sensor generalization than 3D network-based methods.
More details can be found on the project page: https://jingwenwang95.github.io/SeMLaPS/ and in our paper: https://arxiv.org/abs/2306.16585. Please also take a look at this video where Jingwen explains the main contributions of SeMLaPS and shows some results.
Internship Experience at Slamcore
At Slamcore we always welcome internship applications from talented PhD students working on computer vision and robotics who are also hackers and know how to make things work! You will be learning from some of the best researchers and engineers in spatial AI and you will have the chance to publish a paper, file a patent, and show a real-time demo of your work to lots of people in the industry. Take a look at Jingwen’s testimonial about his internship experience at Slamcore: “Interning at Slamcore was a wonderful experience during my PhD. I got to work with many world-leading researchers in SLAM and spatial AI. I learned a lot from them through discussions, meetings and regularly held seminars and reading groups. Everyone was nice and always ready to help you. Here at Slamcore, your research work will not only have the chance to lead to a publication but will also solve actual pain point problems in real development.”
Potential Application in Industrial and Consumer Robots
We are very excited about applying this technology to different applications in industrial and consumer robots. Real-time semantic mapping is a critical component in these applications since robots need to have a semantic understanding of the world, e.g. i. an autonomous mobile robot operating in a warehouse needs to understand where shelves are located to pick certain objects and transport them to a destination and ii. a consumer robot needs to understand the location of the fridge to perform the action of opening the fridge, grabbing a beer and taking it to a user. If you have a robotic application in mind and would like to get early access to this technology please contact us here!
Ends
🤖
Read more at slamcore.com/news
Note: If included in this post, images belong to papers – copyright belongs to the authors or the organization responsible for publishing the respective paper.