
As we are approaching the Christmas holidays and the end of the year we would like to highlight one of the best moments for the robotics community in 2023. Some of the Slamcore members attended ICRA 2023 last May/June in London. We published a previous blog with some conference highlights and some pictures of the great Slamcore event at our office in London Borough. Now, it is the time for a brief review of some of the technical papers in the conference!
Slamcore has begun collating a range of papers and research articles for those concerned with visual inertial SLAM and beyond. Summaries have been developed based on paper/abstract availability. If a paper has been mischaracterized or missed, please contact us.
Note: If included in this post, images belong to the cited papers – copyright belongs to the authors or the organization responsible for publishing the respective paper.
We have clustered the most relevant papers related to visual SLAM and beyond into different categories.
Visual SLAM in Dynamic and Changing Environments
Song et al. presented a visual inertial SLAM system that discards the impact of dynamic features. The approach combines i. a robust visual inertial local bundle adjustment that selectively discards features that deviate from the IMU pose and ii. a robust global backend that groups and clusters similar loop closure hypotheses. The method, named DynaVINS, has source code available here.
Zimmerman et al. presented an interesting method for long-term Monte Carlo-based visual localization in changing environments that uses prior information from sparse CAD floor plans. The method accepts odometry, RGB, 2D LiDAR and CAD floor plans as inputs. An object detection module (the paper uses YOLOv5) is used to enrich the sparse floor plans with semantic information. The source code for this approach can be found here.
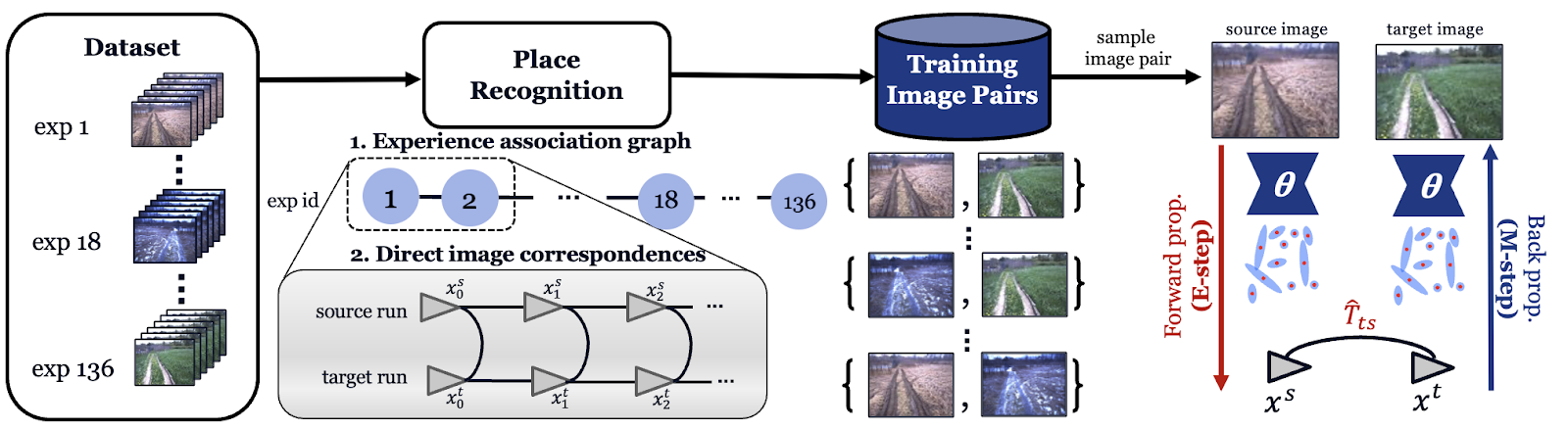
Chen and Barfoot showed an unsupervised learning method that learns features for visual localization tasks with image changes over time. The idea is to use a sequence-based image matching algorithm (e.g. SeqSLAM) to establish image correspondences without the need of ground truth labels. The corresponding image pairs are used for training a deep neural network that learns to predict sparse feature detections and descriptors from images across experiences (e.g. different seasons or lighting conditions). The authors show that the learned sparse features can be used for metric visual localization tasks under different lighting conditions.
LiDAR SLAM
Komorowski et al. presented EgoNN, which is a novel deep learning architecture that extracts local and global descriptors from 3D LiDAR point clouds. These descriptors can be used very efficiently for place recognition tasks and 6 Degree of Freedom (DoF) pose estimation.
Zhong et al. proposed SHINE-Mapping which is a large-scale mapping system for LiDAR sensors based on a hierarchical neural representation with promising results in terms of accuracy and memory usage over established solutions such as Voxblox.
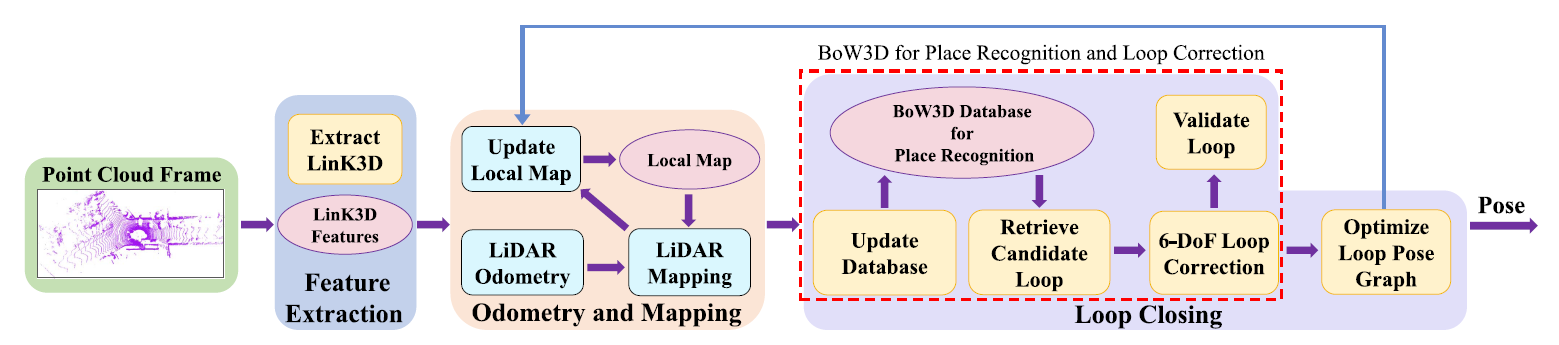
Cui et al. add loop closure detection and pose graph optimization to a LiDAR SLAM system. The loop closure detection uses a place recognition algorithm inspired by Bags-of-Visual-Words, but relies on LiDAR point clouds instead of images. In the proposed system, a Bag-of-Words feature vocabulary is built using the lightweight SIFT-inspired LinK3D descriptors. The paper reports state-of-the-art place recognition from LiDAR scans, and then shows a significant decrease in absolute trajectory errors on KITTI sequences as a result of efficient loop closure detection and pose graph optimization. The source of this method is available here.
Visual SLAM and Sensor Fusion
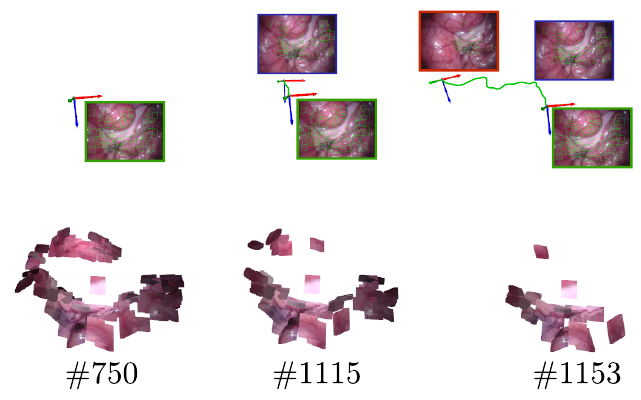
The Direct and Sparse Deformable Tracking method from Lamarca et al. describes the first non-rigid SLAM system which is not based on some global non-rigid model of a deforming body, but rather represents the space as a set of disconnected freely moving surfels. While previous methods modelled the scene as a global deforming model, e.g. a mesh, they suffered from issues with topology changes or geometry discontinuities. The representation proposed in this work allows bypassing of those problems. The method compares well to the prior art in terms of trajectory accuracy and shows good robustness and accuracy on realistic medical intracorporeal sequences.
Cvišić et al. presented SOFT2 which is a very accurate and efficient stereo visual odometry method. The main contribution of SOFT2 is combining in a clever way 2D-2D epipolar geometry errors and kinematic constraints from ground vehicles to perform motion estimation and online scale and camera to camera extrinsic estimation in a bundle adjustment fashion. SOFT2 is still the highest-ranking algorithm on the popular KITTI odometry benchmark which is very impressive!
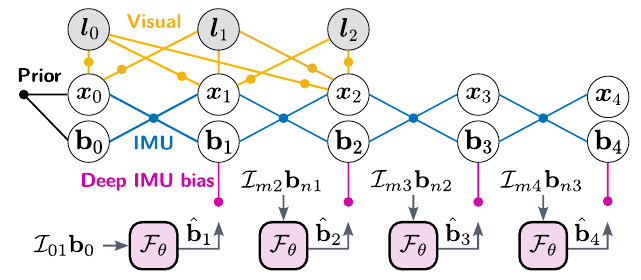
Buchanan et al. presented a deep learning based approach to predict the evolution of biases in a Visual Inertial Odometry (VIO) system. Traditional VIO approaches model the biases as Gaussian errors with a slowly changing transition between consecutives states as a random walk. In this work, the authors propose two variants of deep architectures to predict the biases based on previous measurements using LSTM and Transformers. Experimental results show interesting improvements in accuracy in particular in those cases where feature tracking fails. A minor but very nice and practical contribution is the release of a ROS compatible open source tool for estimating IMU noise model parameters through the Allan variance.
Optimization Methods and SLAM Frameworks
Cramariuc et al. introduced the open source platform maplab 2.0. Its new features include support for multi-robot and multi-modal applications with varying sensor setups. It also features a submap design and central server node, which builds a global map based on information sent by multiple running instances. According to the authors, maplab 2.0 is highly configurable and extensible, which makes it a great framework for research in SLAM. The source code can be accessed from here.
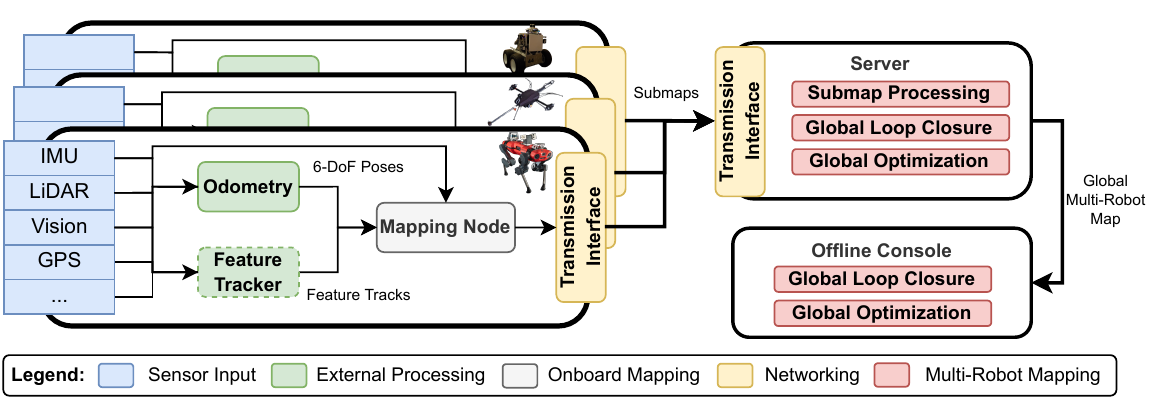
Doherty et al. introduced DC-SAM, a framework for incremental optimisation of mixed continuous and discrete problems, which are ubiquitous in robotics applications. In SLAM for example, the assignments of measurement data association or indications as outliers comprise the discrete variables, and the poses comprise the continuous variables. Many systems determine data association and outliers using robust cost functions and RANSAC prior to the continuous optimisation and often do not (especially in the case of RANSAC) revise them as new information arrives. Instead, DC-SAM treats the discrete variables as “first-class citizens” optimized along with the continuous ones, and incrementally revises minimal sets of them when incorporating new information. As the authors point out, readers familiar with the Expectation-Maximization (EM) algorithm will note the connection. The provision of alternating discrete/continuous minimisation using efficient incremental graph methods by the authors’ high-quality open-source library should be considered by anyone working with such problems in real-world applications.
Solà et al. described their WOLF framework, a high-quality and efficient open-source toolkit for building state estimation systems for robotics out of modular components. The common language for these components is the factor graph, each component ultimately allows a factor graph to be constructed that is solved with any of several available solvers such as Ceres, GTSAM, and others. WOLF also provides integration with ROS. This is clearly a framework built by state estimation engineers! The data generated by the frontend components allows tightly-coupled estimation both of state and calibration parameters, as well as covariance propagation. The authors demonstrate WOLF efficiently solving SLAM problems including LIDAR, camera, GPS, wheel odometry, and other sensors, producing estimates at up to 1 kHz on real-world applications.
Bazzana et al. presented an extension of iterative non-linear least squares for handling constrained optimization in factor graphs based on the well known method of Lagrange multipliers. This interesting new optimization framework shows faster convergence and better run times than traditional solvers for constrained problems, particularly in sparse settings, such as localisation and Model Predictive Control (MPC). The authors show examples of those use cases and propose a pathway for unified optimization of localization and control problems, which can be quite relevant for the active SLAM community.
Calibration
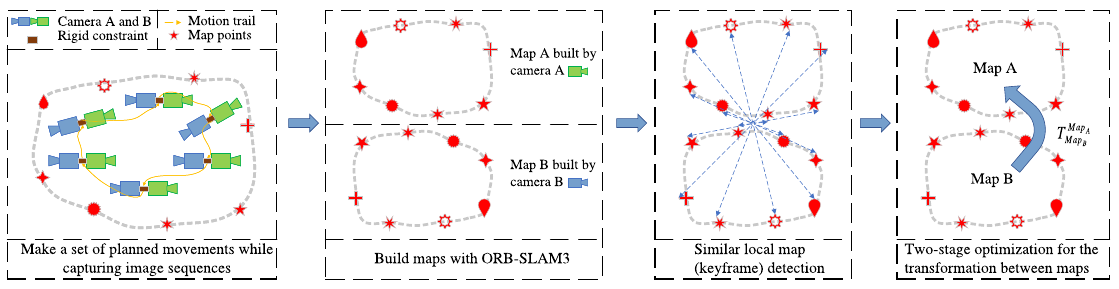
Xu et al. presented CamMap which is a novel method for extrinsic calibration of non-overlapping cameras. The idea behind CamMap is to perform calibration based on visual SLAM map alignment of image sequences from different cameras. The authors use ORB-SLAM3 as the main visual SLAM system but it can be replaced by a different visual SLAM method that produces a sparse 3D map of features and implements a BoW approach or similar for finding image correspondences across cameras.
Benchmarks and Datasets
Zhang et al. contributed the Hilti-Oxford dataset. This amazing dataset, collected on construction sites and also at the Sheldonian Theatre in Oxford, was used in the 2022 Hilti SLAM Challenge. It comprises accurate ground truth and different sensor data such as cameras, LiDAR and IMUs (including temporal and spatial calibration). The dataset contains lots of different scenarios with some challenges for SLAM systems such featureless areas, low lighting conditions, long corridors and dynamic objects. The challenge conclusions demonstrate that a combination of LiDAR and IMU shows the best performance in these difficult scenarios, whereas visual inertial systems struggle much more.
Other
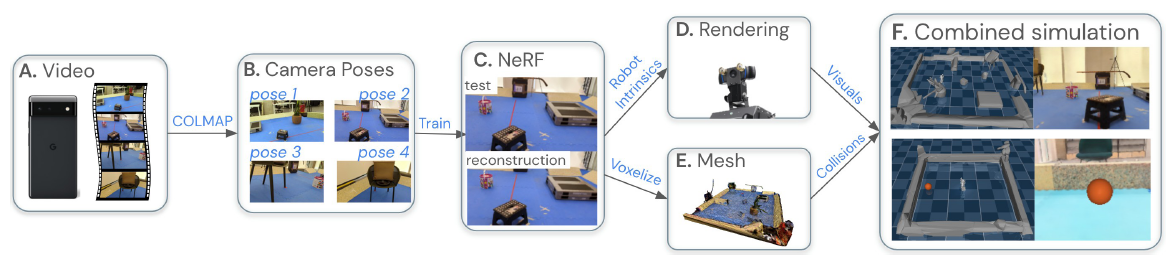
NeRF2Real from Byravan et al. proposes a NeRF-based method for generating novel images for training navigation agents. The method trains a NeRF scene representation that is able to produce 80×60 pixel images consumed during the agent training. The obtained reinforcement learning model can control a real bipedal robot pushing a ball to a given location in a room-scale scene. This work highlights that the modern neural scene representations can synthesise realistic-looking images for training navigation models applicable to real robots. It also demonstrates the limits of those representations, because the ability to generate 80×60 pixel images is clearly not enough to train models that could compete in accuracy with modern visual SLAM systems.
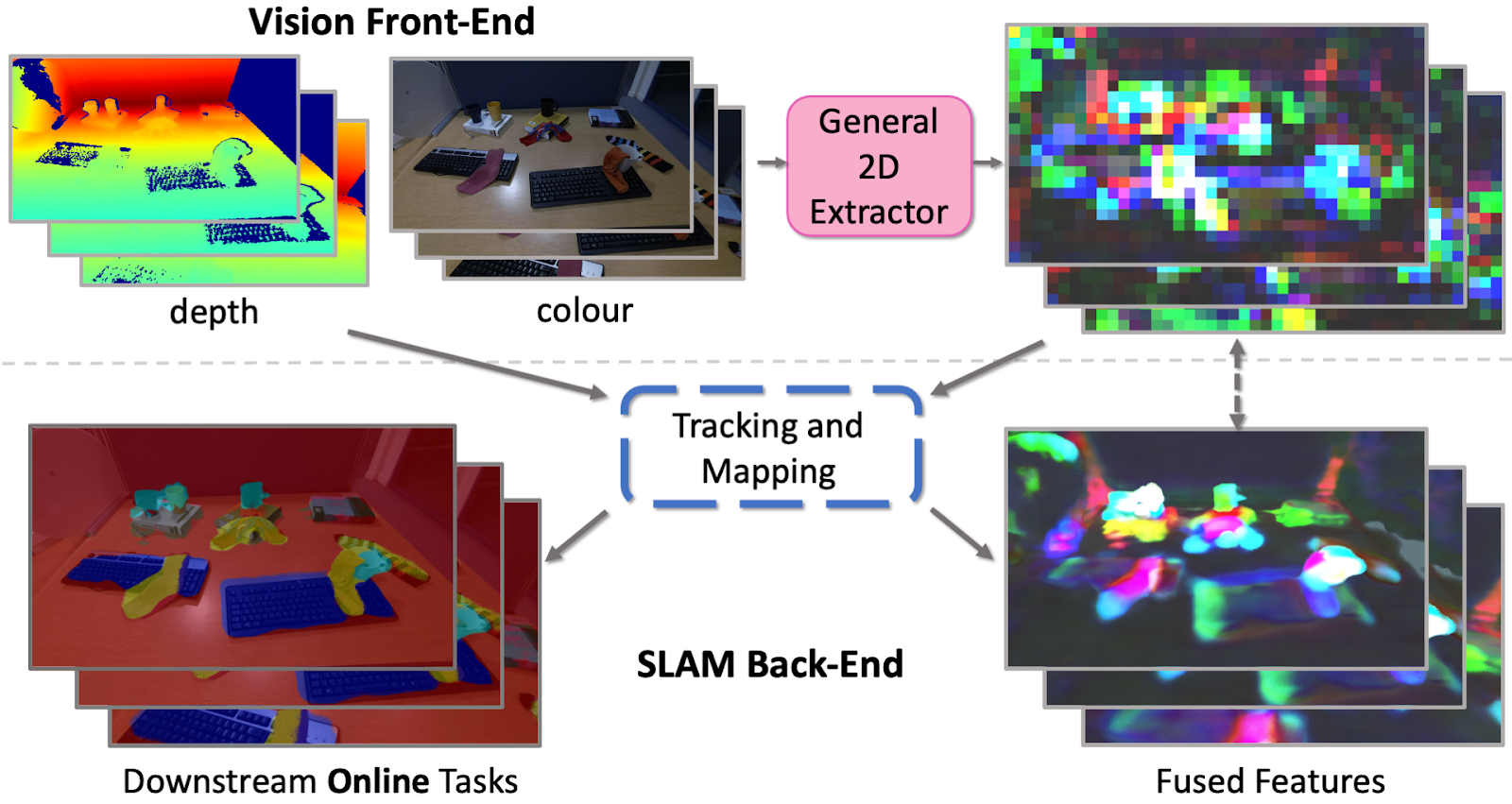
Mazur et al. presented Feature-Realistic Neural Fusion. In this work the authors show how a neural field encoded in an MLP-Nerf Style can fuse feature maps from multiple views into a single volumetric representation. This enables a system where semantic labels of unknown objects (open set) can be propagated in 3D from a few user interactions. Moreover, it is integrated into a SLAM system based on iMAP, showing very interesting use cases for robotics (video here).
Fischer and Milford demonstrated that only a small subset of pixels (but from discriminative image regions) can be used for efficient visual localization when using event cameras which is a very interesting finding for compute and memory constrained platforms.
Special congratulations to the team behind Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems. This work was awarded with the prestigious IEEE Transactions on Robotics King-Sun Fu Memorial Best Paper Award. Kimera-Multi is a very impressive system and it is currently the reference method for multi-robot dense metric-semantic SLAM. The authors kindly contributed the source code of their system to the robotics community.
We hope you have enjoyed reading this blog about ICRA 2023 technical papers. We are looking forward to ICRA 2024 in Yokohama, Japan, where the Slamcore team will be presenting two works SeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation and Orientation-Aware Hierarchical, Adaptive-Resolution A* Algorithm for UAV Trajectory Planning.