It is better late than never! In the IROS 2022 blog we promised that we were going to review some interesting papers from ECCV 2022. The time has finally come and here is our blog for ECCV. Slamcore attended the European Conference on Computer Vision (ECCV) 2022 in Tel Aviv, Israel. There were 6773 submissions and an acceptance rate of 25% for posters and 3% for orals!
Typically one can find more papers about SLAM systems at robotics conferences such as ICRA or IROS. Computer vision conferences tend to focus more on novel computer vision and machine learning algorithms that can be used in different applications. Nevertheless, it is important to keep an eye on these conferences since there are always some interesting works that are important in SLAM systems (e.g. localization, scene understanding, etc.).
Slamcore has begun collating a range of papers and research articles for those concerned with visual inertial SLAM and beyond. Summaries have been developed based on paper/abstract availability. If a paper has been mischaracterized or missed, please email marketing@slamcore.com.
Note: If included in this post, images belong to the cited papers – copyright belongs to the authors or the organization responsible for publishing the respective paper.
Visual Localization
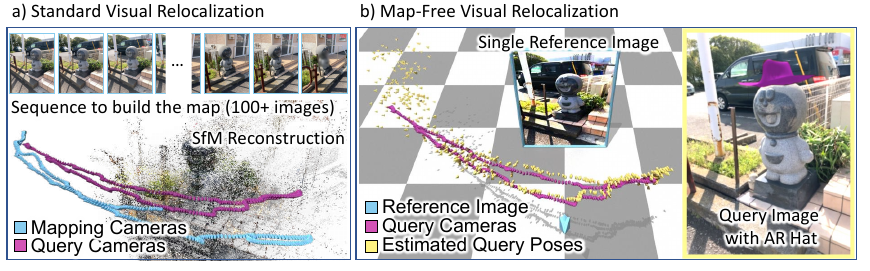
Arnold et al. proposed a map-free relocalization approach, where rather than building a global map from many images for relocalization purposes, a single reference image is used to enable relocalization. The authors introduced the Niantic map-free relocalization dataset that comprises 655 outdoor scenes, each containing a small place of interest (e.g. sculpture, sign, mural, etc.) so that the scene can be well represented by a single image. Relative pose estimation methods are evaluated using the dataset.
Panek et al. investigates the use of dense 3D meshes for localization compared to standard approaches that use Structure from Motion (SfM) based representations. The proposed method MeshLoc: Mesh-Based Visual Localization shows very competitive results when extracting features from renderings of the dense 3D meshes. Source code is available here.
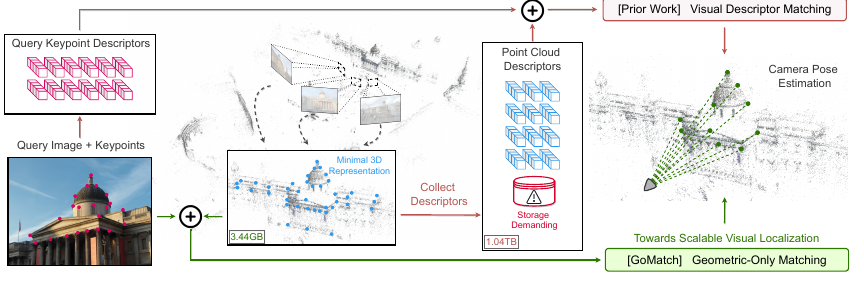
Zhou et al. tackles the problem of visual localization by relying only on geometric information (2D keypoints and 3D landmarks) without the need of using visual descriptors for matching. The authors propose GoMatch, a deep learning-based method for visual localization. A Pytorch implementation of the method has been contributed to the community here.
Benchmarking of localization methods is very important in computer vision. Sarlin et al. introduced the LaMAR dataset for benchmarking localization and mapping methods in Augmented Reality (AR) applications. LaMAR is a large-scale dataset captured using AR devices (HoloLens 2, iPhone) and laser scanners.
Visual SLAM in Dynamic Environments
Visual SLAM does typically make the assumption of a rigid scene. However, in reality one needs to face environments with dynamic objects that make the SLAM problem more challenging. Henning et al. proposed BodySLAM, which is an interesting monocular SLAM system that jointly estimates the position, shape, and posture of human bodies alongside the camera trajectory all in a factor graph formulation.
3D Reconstruction and Depth Estimation
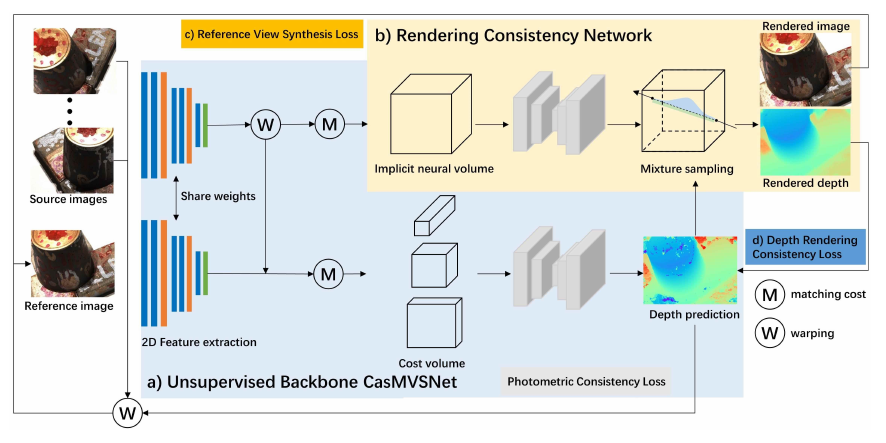
Chang et al. proposed a novel approach for unsupervised multi-view stereo RC-MVSNet. The main novelty relies on using neural rendering for supervision of a Multi-View Stereo (MVS) network. One of the main challenges of unsupervised MVS is finding correspondences across different views. Most of the methods make the photometric consistency assumption which may not hold true in many real scenarios due to non-Lambertian surfaces and occlusions. The source code of RC-MVSNet can be found here.
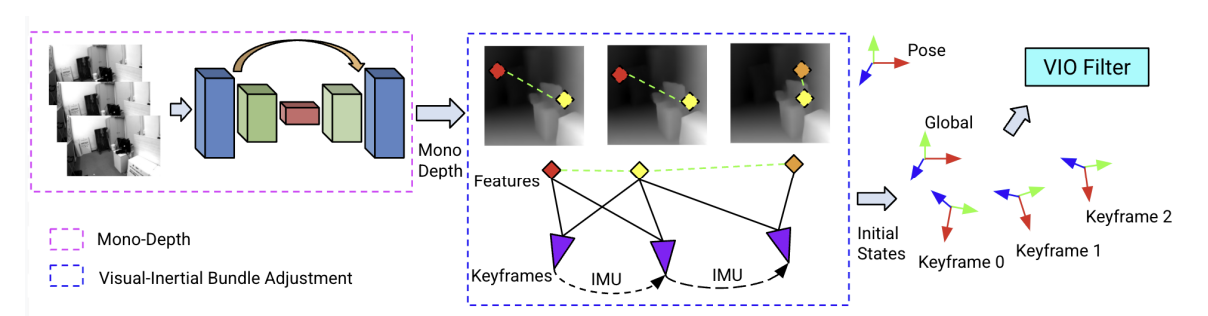
Zhou et al. Proposed Learned monocular depth priors to tackle initialization in Monocular Visual-Inertial Odometry. Initialization in monocular VIO is a key problem as unless the user provides relevant motion, the system cannot infer the 3D structure correctly, leading to ambiguities which result in position drift. In this work the authors propose to use Mono-Depth as initialization for the features position in a VIO system, integrating these measurements into the optimization problem.
In Sayed et al. it is shown how state of the art 3D reconstruction can be achieved in real time using a more “traditional” pipeline of Multi-View Stereo and T-SDF fusion. Most current SOTA 3D reconstruction methods fuse features into a 4D cost volume which is later processed with 3D convolutions: this is very expensive! Using 2D CNNs to encode multiple views into a cost volume and incorporating meta-data readily extracted from frames relative position this system is able to achieve impressive per-frame depth quality with a much cheaper MLP reduction of the cost volume, neat!
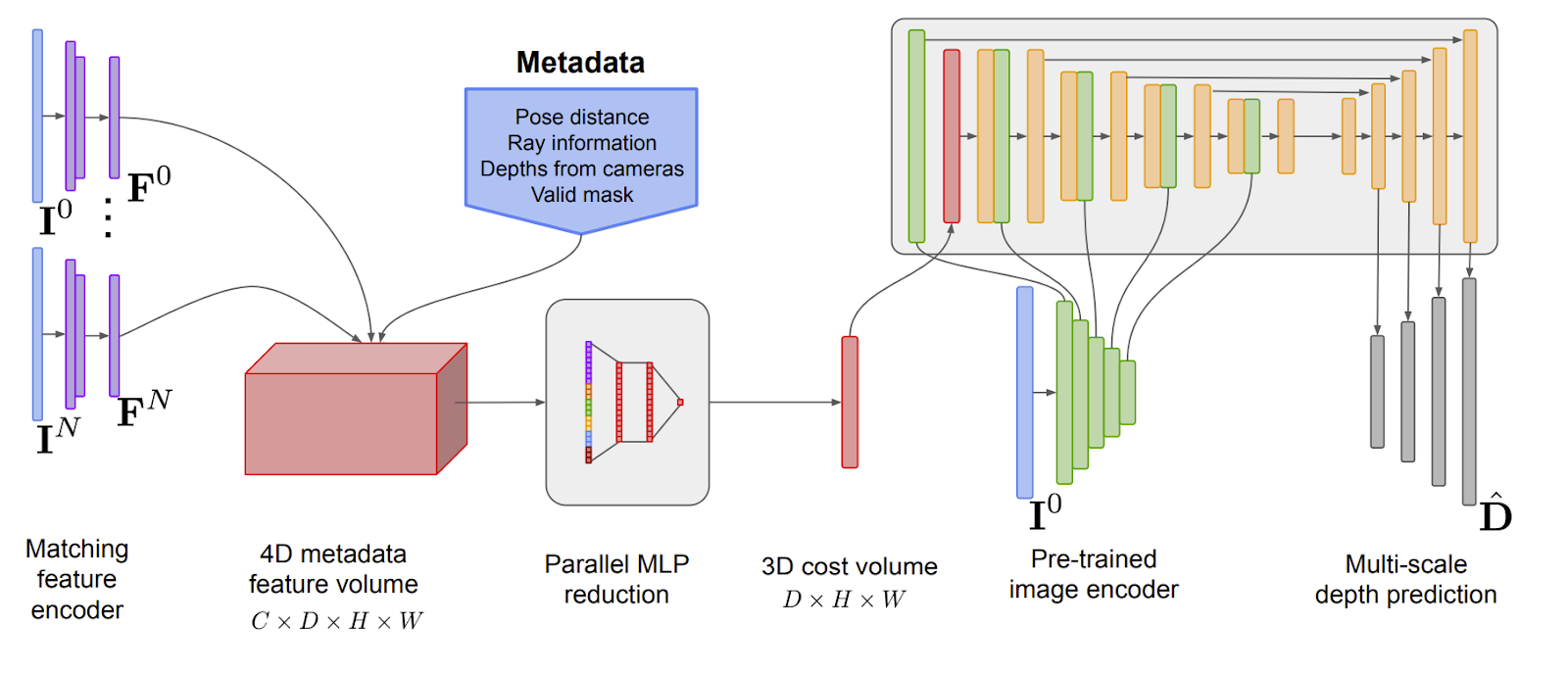
3D Semantic Reconstruction
Rozenberszki et al. presented both a benchmark and a methodology for 3D Segmentation with a large number of categories. The ScanNet200 benchmark features 200 classes (vs. 20 in the original ScanNet) and is well aligned with a recent effort in the community of addressing this more general open set problem. To tackle segmentation in this context, the authors propose to use CLIP text features encoded from the labels themselves to ground the output features of a 3D NET using contrastive learning; showing how this grounding can learn to a better structure of the representation space. They also implement interesting augmentation techniques to tackle class imbalance, a significant problem as the number of classes grow and some of them unfailingly become rarer.
Change Detection
Change detection is a very important problem in SLAM and robotics. In order to efficiently update maps over time, it is critical to detect those changes in the images and propagate the updates to the map. Adam et al. proposed a change detection method based on 3D object discovery. Changes are first detected by checking differences in depth maps and then segmented if they undergo rigid motions. A graph cut optimization process refines the detected changes and propagates the changing labels to geometrically consistent regions. Results are evaluated on the 3Rscan dataset and source code was kindly provided by the authors in GitHub.
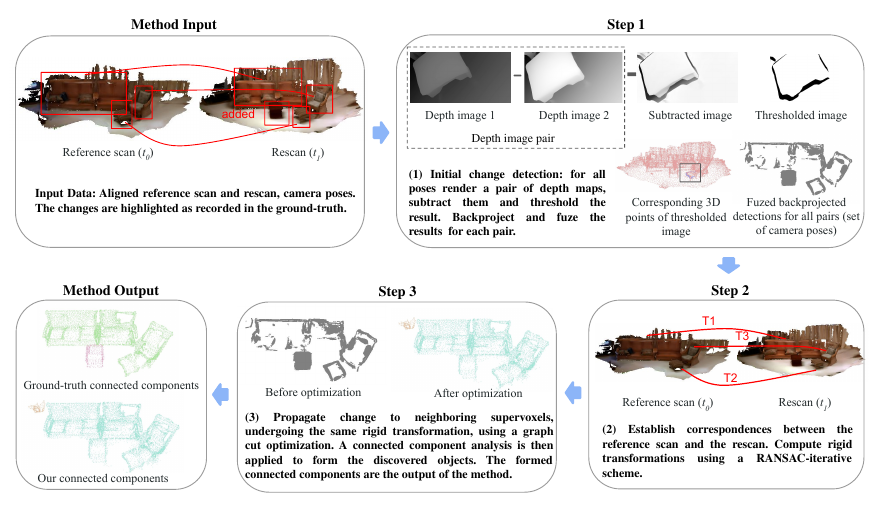
Others
It is always nice to see that classical computer vision still has a place in ECCV! In relative pose from SIFT features, Barath and Kukelova show how the orientation and scale provided by the SIFT extractor can be used to devise new epipolar constraints that can be used to improve Fundamental and Essential matrix estimation, and in general feature based localization.
In NeFSAC Cavalli et al. aims at improving RANSAC efficiency and performance by training a lightweight network to early filter ill-conditioned minimal samples. Most of the computational cost in RANSAC comes from scoring each minimal sample proposal, which normally implies regressing the model and going through the whole set of samples to count the number of inliers. By training a network to predict the quality of the sample based on probable motion and feature distribution NeFSAC can quickly filter out proposals, achieving a significant increase in performance.
In Scene Graph Generation we aim at computing a graph that encodes relations between objects, Person -> on top of -> bench -> on top of -> grass. Such representation can be extremely useful for scene understanding in robotics. In Yang et al. they propose to do this Panoptically instead of using bounding box detection. For this they propose a dataset and a benchmark and propose PSGFormer, a DETR based model for single pass panoptic scene graph generation.
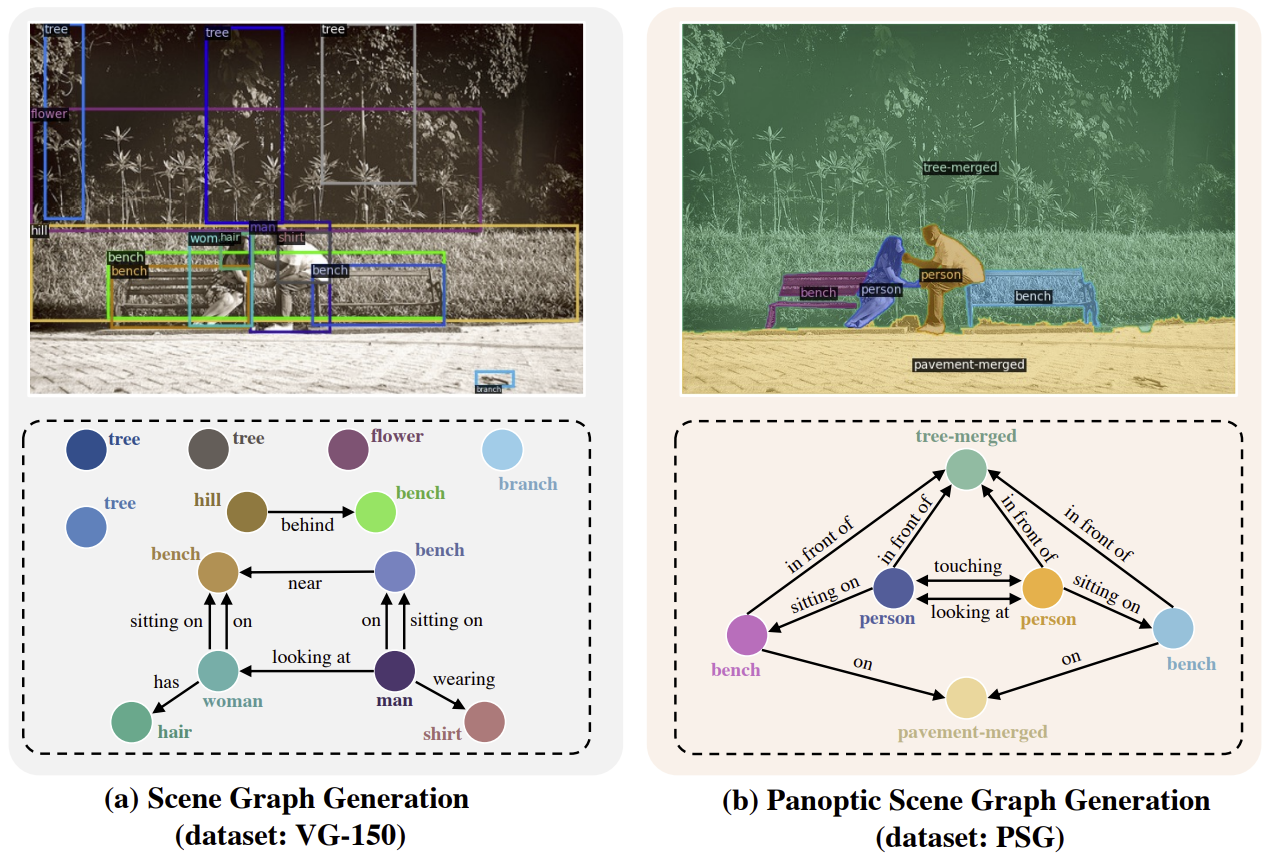
Best paper mention
Aiming to bridge the gap between explicit and neural implicit representations Mehta et al. seem to take the best of both worlds. Implicit SDF surface representations parameterized with an MLP can represent incredibly complex topologies, but how to optimize them efficiently? In this work a connection with traditional evolution of explicit meshes is established, a methodology which has been widely studied in computer graphics. A great limitation of these methods has classically been handling topology changes in meshes, however, if the representation is implicit, we can evolve a sphere into a wireframe bunny…

We hope you have enjoyed reading this blog (better late than never!). As mentioned in our ICRA 2023 recap blog, we are working on our next blog about technical SLAM papers presented at ICRA 2023 in London recently!